How ChatGPT Works: 5 Simple Steps to Unterstand the Architecture

ChatGPT may seem like magic: You enter a few words, and voilà – tasks are solved, texts are written, world peace? Well, almost. But instead of a magician, behind ChatGPT is nothing other than the Generative Pre-Trained Transformer. Generative Pre-trained Transformer – sounds complicated, right? But don’t worry, we’ll break it down for you. If you’re wondering what exactly is behind this impressive technology, then you’ve come to the right place. Let’s take a closer look at the three key aspects that make ChatGPT so powerful.
- Generative: The model generates new content (like text) based on the inputs it receives.
- Pre-trained: ChatGPT is trained on vast amounts of text to understand language and context before performing specific tasks.
- Transformer: The architecture powering GPT processes large amounts of data efficiently, considering the context and meaning of words.
Introduced in the 2017 paper “Attention is All You Need“, the Transformer architecture enables models like ChatGPT to process data in parallel. It uses self-attention mechanisms to determine the importance of different text parts. To better understand this, let’s break down the five phases involved in processing text with ChatGPT. The following diagram illustrates the process, from input to final response.
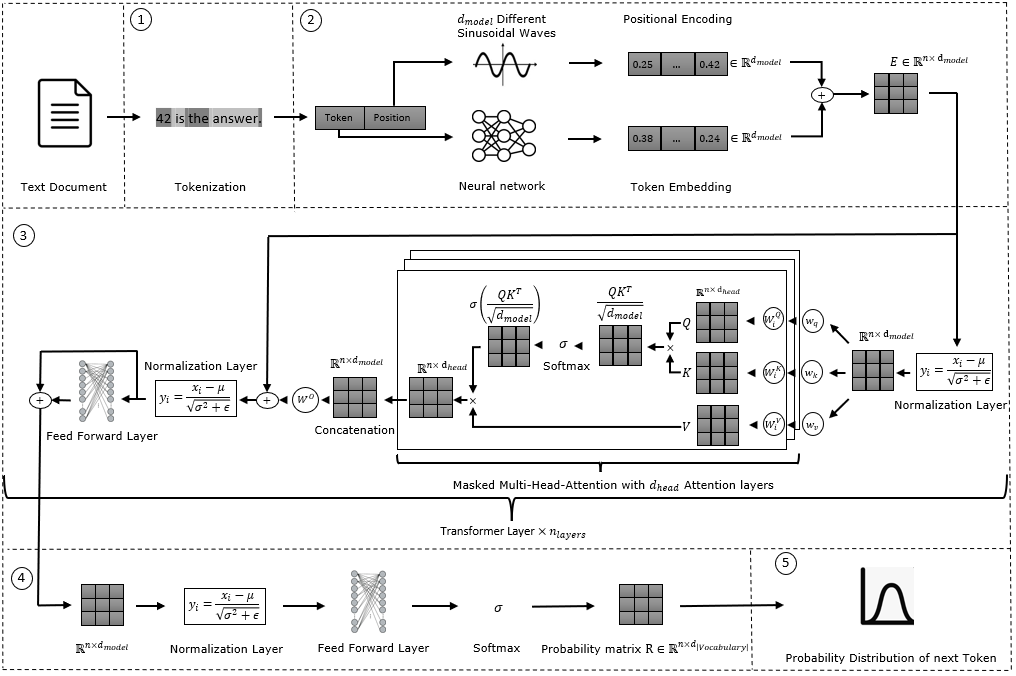
Step 1: Tokenization – Breaking Text into Small Units
To process text data, ChatGPT begins by tokenizing the input. This means breaking the text into smaller units, called tokens, which represent words, letters, or punctuation marks. ChatGPT uses the Byte Pair Encoding (BPE) algorithm for tokenization. For example, the sentence “42 is the answer.” is broken down into the tokens: [“\(42\)”, “is”, “the”, “answer”, “.”]. (You can try out the Tokenizer yourself.)
Step 2: Token-Embedding and Positional Encoding – Turning Tokens into Numbers
Step 3: Transformer – Attention on Important Words
Transformer layers help understand the relationships between words in the text. First, the input is normalized to make the training process faster and more stable. Then, the input matrix \(E\) is multiplied by the weights \(W_q, W_k, W_v\) to obtain the Query (\(Q\)), Key (\(K\)), and Value (\(V\)) matrices. Each matrix column is identical, meaning each token representation is scaled by the same factor.
Why use three different token representations? It’s essential for two key steps: calculating the similarity between tokens and determining the relevance of one token to another. This process is called Masked Multi-Head Attention. “Masked” means each token’s attention is only calculated for previously seen tokens in the sentence, ensuring the model focuses only on words generated so far during text generation.
First, the Query and Key matrices are multiplied, and the result is scaled by the square root of the model dimension \(d_{model}\) (\(\frac{QK^T}{\sqrt{d_{model}}}\)). Each token in the resulting matrix is now associated with a vector encoding its similarity to other tokens, including itself. The Softmax function is then applied to these values, producing weights between \(0\) and \(1\), which determine how much each token contributes to the attention values of the others.
Next, the calculated weights are multiplied by the Value matrix (\(V\)) to obtain the attention values for each token. The input matrix \(E\) is added to the attention matrix, ensuring the model retains the original token information while learning about their contextual relationships. The final Transformer layer includes Layer Normalization and a Feed-Forward Layer, which prevent fluctuations and allow the model to learn additional complex features.
Step 4: Feed-Forward Layer and Probability Distribution
After the Transformer layer, the model normalizes the data and applies a linear transformation to map the output to the vocabulary space (number of tokens). The softmax function then produces a probability distribution, represented by the matrix \( R \in \mathbb{R}^{n \times |V|} \). Each entry \( r_{ij} \) represents the probability that the token in row \(i\) (the current token) is followed by the token in column \(j\) (the predicted next token).
Step 5: Predicting the Next Token
Once trained, GPT generates text by predicting the next most likely tokens based on the learned probability distribution. It continuously updates the context by adding the next tokens to the sequence until the final token completes the sentence. The sequence with the highest probability is selected as the output.
Conclusion – The Magic behind ChatGPT
At first glance, ChatGPT might seem like magic. But now you understand it’s based on tokenization, attention mechanisms, and clever engineering. By breaking text into tokens, understanding context with the Transformer architecture, and predicting the next word, ChatGPT turns complexity into simplicity.
ChatGPT is a cutting-edge Large Language Model (LLM) that leverages vast datasets and advanced natural language processing (NLP) techniques to generate human-like text. Its ability to dynamically update context and deliver coherent responses makes it one of the most advanced AI models today. From summarizing articles to creating content, LLMs like ChatGPT are transforming how we interact with technology.